There is a specific kind of confidence that comes from watching a test suite go green. Not the confidence of “I think this works” but the confidence of “a headless browser just clicked through every flow, checked every assertion, and nothing broke.”
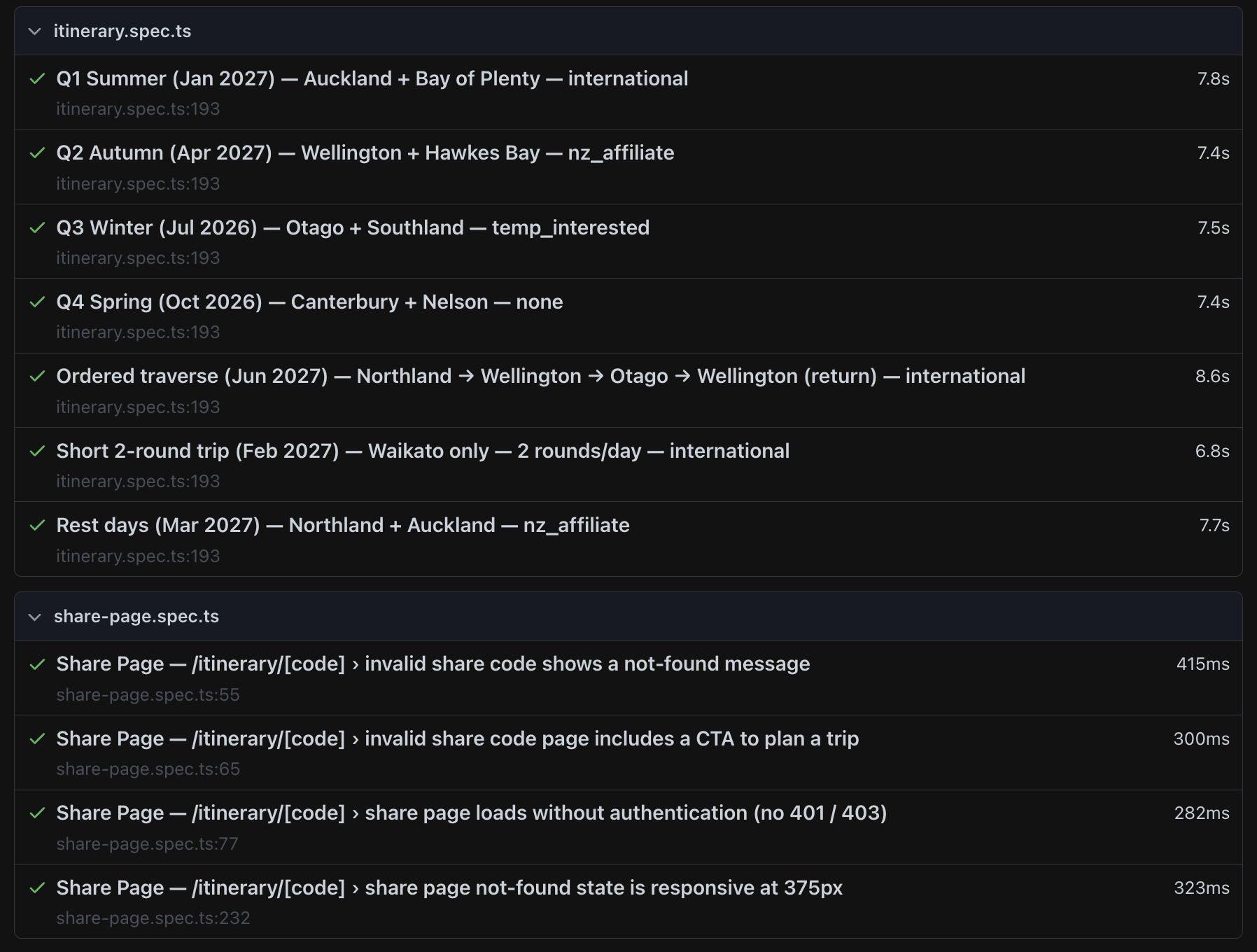
FairwayPlan has eleven end-to-end tests. That does not sound like a lot. But each one fills out a five-step wizard, waits for a MIP solver to generate an itinerary, and then verifies everything from the UI rendering down to the database records. A single test exercises the frontend, the API proxy, the backend, the optimiser, the weather service, and PostgreSQL. If any of those layers break, the test fails.
Why end-to-end, not unit tests
I have unit-test instincts from years of backend work. Test the function, mock the dependencies, check the output. But the bugs that have actually hurt FairwayPlan in production were never inside a single function. They lived in the seams.
The asyncpg JSONB codec issue is a good example. Clothing recommendations came back as double-serialised strings, and it would have passed any unit test. The function returned the right data. The database stored the right data. The problem was that asyncpg silently serialised it again on read, and the frontend received a string where it expected an object. Only a test that went browser-to-database-and-back would have caught it.
The nginx upstream resolution bug from the last deploy would have passed too. The application code was correct. Every service was healthy. The failure was in how nginx resolved container hostnames at startup. No unit test covers that.
End-to-end tests are slow, flaky, and annoying to maintain. They are also the only tests that check whether your application actually works.
The bugs that actually hurt were never inside a single function. They lived in the seams between services.
What the tests cover
The itinerary suite runs seven scenarios, each representing a different combination of season, region, and golfer affiliation:
- Q1 Summer: Auckland and Bay of Plenty, international golfer. Peak season, maximum course availability.
- Q2 Autumn: Wellington and Hawkes Bay, NZ affiliate. Shoulder season, tee-time windows start narrowing.
- Q3 Winter: Otago and Southland, interested in a temporary membership. Cold-weather gear should appear in clothing recommendations.
- Q4 Spring: Canterbury and Nelson, no affiliation. Different pricing tier, different course selection.
- Ordered traverse: five regions in a specific order, verifying the solver respects the requested sequence.
- Short 2-round trip: Waikato only, two rounds per day. Tests the edge case of a minimal itinerary.
- Rest days: Northland and Auckland, ensuring the solver inserts rest days when the trip is long enough.
The share page suite tests four things: invalid codes show a 404, the not-found page includes a call-to-action, valid share pages load without authentication, and the layout is responsive at mobile widths.
What each test actually checks
Every itinerary test does more than confirm the page renders. After the wizard completes and the itinerary appears, the test:
- Verifies that day cards are visible and contain course names.
- Checks that clothing recommendations are an object, not a string. This is a direct regression test for the JSONB codec bug.
- For winter scenarios, asserts that cold-weather items like thermals or rain gear appear in the recommendations.
- Queries the database directly to confirm that the trip, itinerary, and slot records match what the API returned.
That last step matters. The test does not just check the UI. It opens a direct PostgreSQL connection and verifies the data. If the API returns one thing and the database contains another, the test fails.
Solo projects need tests more, not less
On a team, someone else reviews your pull request. They catch the typo in the SQL migration. They notice you forgot to handle the null case. They ask why the API response shape changed.
When you are the only developer, there is no second pair of eyes. The test suite is the reviewer. It does not get tired. It does not skip the edge case because it is Friday afternoon. It runs the same checks every time, including the ones you would have forgotten to check manually.
On a solo project, the test suite is your only colleague who never takes Friday afternoon off.
I have deployed changes to FairwayPlan that I was certain were safe. Trivial CSS tweaks, copy updates, config changes. The test suite caught regressions in three of them. The changes themselves were fine. They just interacted with something I was not thinking about at the time.
AI as a testing partner
Writing tests is one of those things that every developer knows they should do and most solo developers skip. The reasoning is always the same: writing tests takes time, the feature already works, and there are twenty other things on the list. When you are the only person on a project, test coverage is the first thing that gets cut.
AI assistance changed that equation for me. The entire Playwright suite was built with Claude Code. I described the wizard flow, the scenarios I wanted covered, and the assertions that mattered. It wrote the page object helpers, the database verification queries, the test fixtures. What would have taken me a full weekend of context-switching between Playwright docs and my own codebase took an afternoon.
The speed matters because it removes the excuse. When writing a test takes thirty minutes instead of three hours, you actually write it. You add the edge case. You add the regression check for the bug you just fixed. The barrier drops low enough that testing becomes part of the workflow instead of a separate project you never get around to.
It is not just the initial writing either. When I added the share page feature, I needed four new tests. I described what the share page does, what should happen with invalid codes, and what the mobile layout should look like. The tests were written and passing within the hour. Without that, I would have shipped the feature with manual QA and moved on. The share page would have zero automated coverage today.
The cost of not testing
The alternative to automated tests is manual testing. Open the site, click through the wizard, pick some regions, wait for the itinerary, eyeball the results. That takes about three minutes per scenario. With seven scenarios, you are looking at twenty minutes of clicking. And assuming you actually test all seven, which you will not, because you are human and you will skip the ones you think are fine.
The Playwright suite runs all eleven tests in about a minute. It runs them the same way every time. And it checks things a human would never bother to verify manually, like whether the database records match the API response or whether the clothing recommendation is the right data type.
Eleven checkmarks
It is not a large test suite. There are no visual regression tests, no load tests, no chaos engineering. But those eleven tests cover the paths that matter most: can a user plan a trip, does the solver produce a valid itinerary, do the share pages work, and is the data consistent from browser to database.
Every deploy starts with make tests. If something is red, I fix it before pushing. The suite has caught real bugs that would have reached production. That is all a test suite needs to justify its existence.
Eleven tests, one minute, every deploy. That is a cheap insurance policy for a solo project.